Adam Day










Adam Day
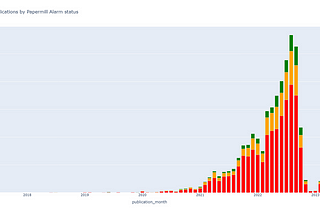
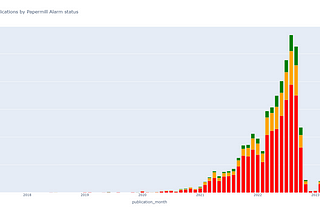
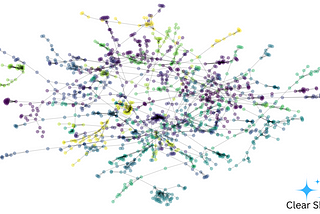
Creator of Clear Skies, the Papermill Alarm and other tools clear-skies.co.uk #python #machinelearning #ai #researchintegrity
Creator of Clear Skies, the Papermill Alarm and other tools clear-skies.co.uk #python #machinelearning #ai #researchintegrity