Oversight, by Clear Skies, is the first complete index of journal integrity. Oversight takes complex data on research integrity and enables a straightforward and intuitive understanding of every journal in the world.
We rank journals based on analysis of data from our extensively field-tested integrity tools. The Papermill Alarm is used by dozens of publishers and we routinely test and iterate our analysis on the last decade of published papers.
Here we present a Composite Risk Score which helps publishers to identify risk in their portfolios.
Contact us to learn more.
Measuring how well journals are doing is challenging. What’s a good way to measure that? If we want to make Key Performance Indicators for journal success, we might try:
- How many papers does the journal publish?
That’s an easy one to measure. And, while it’s a nice objective metric, we’ve seen in recent years how rapid growth can often be a sign that a journal has been targeted by fraudsters — and that can lead to lost growth and to reputational harm in the long run.

Another metric for success:
- How many citations does it have?
Citations are like votes: it’s like one paper is telling another “I think you are a good paper”. So it follows that a journal with a lot of inbound citations to its papers must also be good.

This works to a point, but we know that where papermills target journals, they often cite their past publications in those journals, so — again — the metrics might look great, but where there’s fraud, more papers and more citations aren’t necessarily a good thing — they might actually represent growing risk.
Look at it this way, what if a journal only cites papermills and is only cited by papermills? When we put the journal into context like that, the citations are actually a good way to measure its problems.
So, when we want to measure integrity, citations have a very different meaning to when we want to measure usage.
Integrity Screening
The Papermill Alarm is a mix of machine learning and network analysis on scholarly metadata. It flags strong indicators of organised research misconduct in research text and metadata. As organised fraud develops, patterns change and our methods adapt to detecting them.
Oversight tracks 100% of scholarly journals and allows an intuitive measure of the integrity of each one. Oversight offers analysis of every paper published since 1 January 2016 and aggregates that analysis at the journal level. That’s around 60m papers.

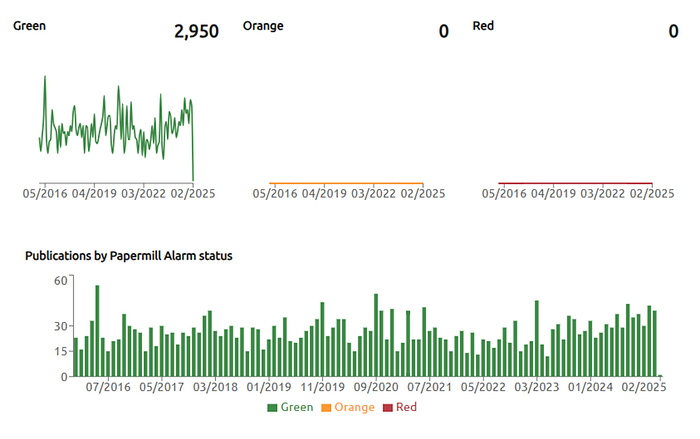
Here’s a good example. This is a journal called Classical and Quantum Gravity (CQG). I’m biased here. I managed CQG up until 2015 and I’m pleased to see it doing well! We focused on strong peer-review at CQG and I think that this graph — all green with no orange alerts or red alerts — is an indication that peer-review pays off.
This journal, by contrast, may have some issues worth investigating.
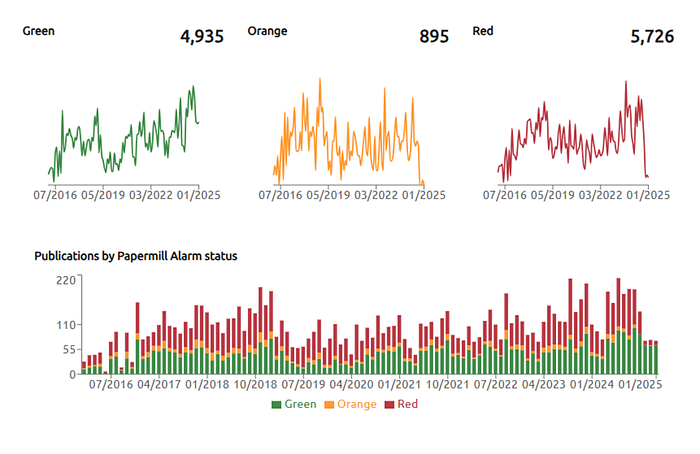
I won’t say which journal this is (I will say it’s not one of mine), but finding an example like this using Oversight took just seconds, because it’s big.
Right now, Oversight orders journals by their raw count of Papermill Alarm alerts. So all we have to do is sort by number of alerts and big targeted journals are simple to find. We’ve seen before how large journals stand out when we do this.
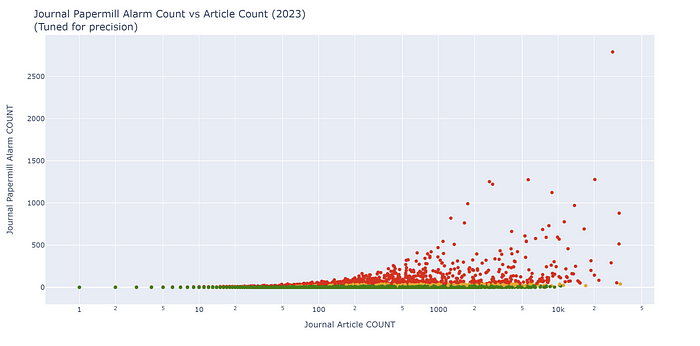
But what if we want to keep an eye on journals of any size? We could add a filter for percentage of alerts. That’s certainly useful, but what happens is that you find a number of very tiny journals top the list and the big journals with the most significant problems almost disappear.
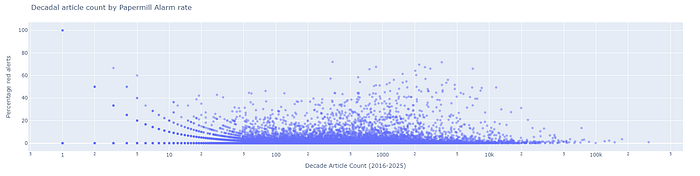
So let’s find a way to balance that out, so that we can find everything in the middle and achieve greater granularity in ranking small journals — in fact, let’s see if we can get greater granularity in ranking journals of any size.
In summary:
- we have an index of journals which we can order by a proxy for the risk presented by papermills and other forms of organised misconduct.
- That’s a very useful thing because it can help an editor or publisher to develop their journals, keep fraud at bay and demonstrate value to authors.
- But we also have the largest dataset of research fraud in the world and a giant network of data describing the journals in Oversight.
How can we leverage that network of data to find the most urgent cases?
PageRank for Papermills
Remember Keystone? The Keystone analysis from Clear Skies was the first commercially available network analysis for detecting bad actors in publication metadata. It’s based on a concept called ‘network centrality’. Authors are connected to papers, to one another, to institutions etc. Here, we are treating those connections to individuals as ‘votes’ so a vote might be something simple like
- We find a problem paper
- We connect that to its author
- That’s like the paper is voting for the author
Importantly, an author has to get a lot of votes before they would have high enough ‘centrality’ to trigger an alert with Keystone. So errors, bad data, spurious connections etc don’t inadvertently affect individuals.
Aside: we are extremely careful with personal data at Clear Skies and we only share data from Keystone after following a documented decision-making process.
Maybe we can make Keystone work for journals, too. But what’s the best way to count those votes? Just literally count them? What about old votes — do those still matter, or should they be ignored after some time? Are some votes more significant than others? Will big journals get more votes than little ones? It’s a tough one!
Remember how I said that citations are like votes? Larry Page, one of the co-founders of Google, made a similar analogy in a famous paper where he introduced ‘PageRank’, an efficient method for ranking webpages (it’s based on something called ‘Eigenvector Centrality’).
PageRank treats a link from one webpage to another like a vote. So a link is like one webpage is telling another: “I think you are a good webpage”. This implies that websites which receive a lot of inbound links are considered to be more reliable than those with fewer inbound links.
But here’s the brilliant part:
- webpages with a lot of inbound links have high ‘importance’.
- This means that their outbound links are given greater ‘importance’, too.
- This creates a process where a measure of importance becomes automatically distributed around the network (and that measure of importance is called PageRank).

PageRank allowed Google to easily rank webpages by importance. It works incredibly well at scale. Billions of people have relied on PageRank to surface important information for decades at this point.
PageRank is partly responsible for the early success of Google. But it turns out that the algorithm is also highly successful in network analysis and has applications in fraud detection. Some years ago, I used PageRank to assign a rating to authors believed to be associated with papermills. Here, you could think of PageRank measuring votes in the opposite way. Imagine we have a lot of noisy signals suggesting that a user’s account is problematic. Using PageRank, we can treat those like votes to find the most important cases for investigation.
So here’s an idea
There are a few reasons why we can’t simply run PageRank on our data, but we can adapt the algorithm to our use-case using data from the Papermill Alarm. Let’s call this metric “AlarmRank”.
What we’re looking for are signals which are like one journal saying to another, “I think that paper is untrustworthy”. And when you treat all of those like votes, you find which journals are most at risk.
Example voting mechanism
- I am a fake paper.
- Another paper cites me.
- But I know I am a fake paper, so I know that citation shouldn’t be there.
- So that means I can infer that other paper is likely to be unreliable and I cast my vote. The fake paper is voting that the citing paper is unreliable.
- So, in this example: when we apply AlarmRank, we can see which journals tend to cite papers which we know to be fake.
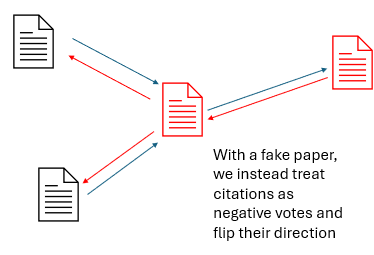
The voting mechanism is passive. An article triggers our integrity screening checks, and then silently ‘votes’ for every journal that cites it. Importantly, just doing this once or twice has little effect on most journals. So if authors make occasional mistakes and cite bad papers from time to time, that’s ok. It has to fit a pattern to be significant.
This method has a lot of benefits:
- The findings that cause the ranking can be shown transparently for the publisher to help them to investigate.
- It scales to the full list of journals and other sources in Oversight (currently over 100,000 sources are tracked including every journal in the world).
- It has all the known benefits of PageRank: robust, reliable and difficult for bad actors to game.
Significantly, there is a temporal component in AlarmRank. That means that we are looking for journals with high risk now. So, if we just count Papermill Alarm alerts in a journal, for example, we might find a discontinued Hindawi journal tops the list because it had alerts in the past. Given that there were well-documented problems there, that is a good confirmation of the methods, but it isn’t very useful if we want to know whether a journal has high risk now.
As people become more aware of the organised nature of research fraud, those organisations that commit fraud at scale are adapting. They moved away from Hindawi very suddenly and targeted other journals. Good network analysis helps us to track them. But it also means that, if a journal has had problems in the past and those are now dealt with, the AlarmRank returns to normal. The publisher can still easily find historic articles to investigate using Oversight, but AlarmRank will give the current picture.
It’s highly adaptive.
An Integrity Rating
Clear Skies can go one very big step further. The Papermill Alarm has had extensive real-world experience. We routinely analyse 10s of millions of papers and journal submissions with a range of methods. We constantly iterate on that analysis.
We would never claim that it is perfect, but the outcome is that we can confidently say that we have the largest database of fraudulent research in the world. This means that, when we run the analysis above, we can use high quality data on authors, institutions and journals to give us the best possible outcome.
This gives us a Composite Risk Score:
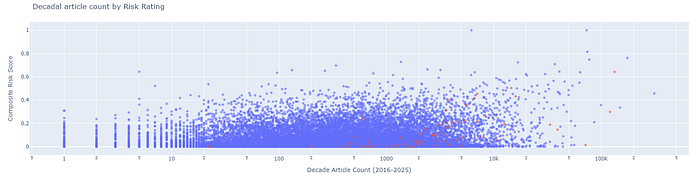
- Importantly, we can’t just use AlarmRank for data quality reasons. Some publishers only put out partial data and we need to work around that to create a composite score.
- But here we can see a granular risk rating across journals of all sizes.
- The red ones are journals that have had mass retractions in the last decade. We define a mass retraction as any retraction of 30 or more papers by one journal inside one calendar year.
- The red dots with high risk scores have all had those mass-retractions recently and have retracted recent articles.
- The red dots with low risk scores (at the bottom of the plot) are mostly Hindawi journals. We predicted those, but importantly, because those journals do not have concerns right now (they are mostly shut down and no longer publishing), they have dropped to the bottom of the rankings. They are still findable in the data, but they are not considered to be high risk right now.
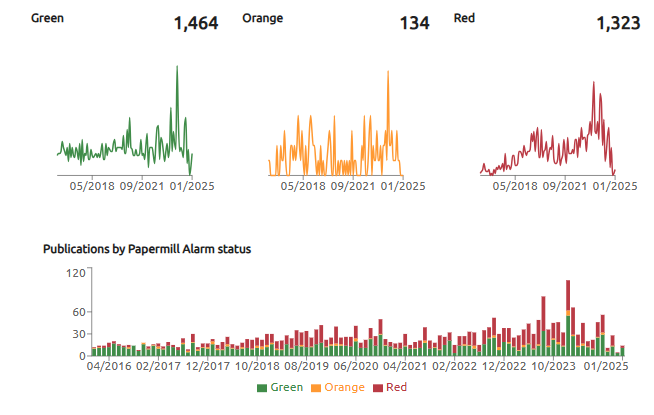
So, we have a reliable metric for integrity that is incredibly good at finding journals of any size that are at risk. Like this one. It’s a mid-size journal with a lot of recent alerts.
Or this one. It’s a small journal, but it has recent growth in alerts.
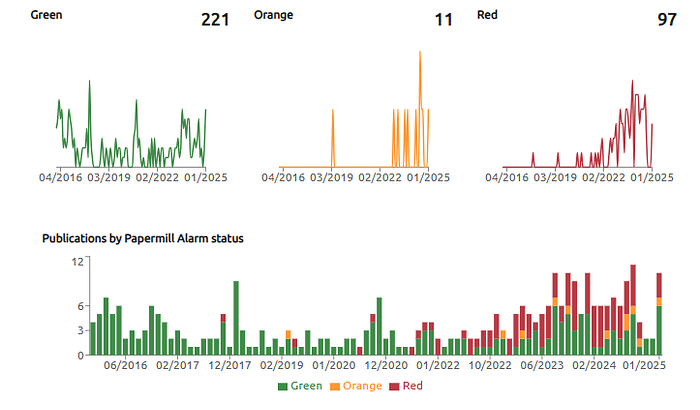
Or even this one. It doesn’t have a high score and has just 1 alert, but the AlarmRank is high enough that it stands out above other journals which also have just 1 alert. The journal is tiny and hasn’t published anything for over a year. With a journal this size, I can imagine that it might only be one of many journals in an editor’s portfolio. Knowing about an event like this as soon as it happens is important for an editor with diverse responsibilities.

So, there we are. We have a verifiable method of assigning risk to journals which we can now apply to every journal in the world. Publishers can use Oversight to detect risks in their portfolios and address those risks. It’s robust, reliable, hard to game, and easy to understand. The same rating system can be applied to articles, institutions, funders… but maybe we’ll come back to those in future posts.
